
My Travel Blog GPT
Step-by-step on how / why I built the "Jack Travel Blog GPT."

Welcome to Young Money! If you’re new here, you can join the tens of thousands of subscribers receiving my essays each week by adding your email below.
Summary:
I fine-tuned OpenAI’s GPT-4o mini by feeding it the full history of my travel blogs, and the result is that I now have a “Jack Travel Blog GPT” that can create travel blogs, in my tone, based on prompts such as, “Write a travel blog in Jack’s voice about his trip to India for his friend Tanmaye’s wedding. His friends Antonio and Ben tagged along as well.”
I can create these by either calling the model in my own terminal, or by running it in an OpenAI Sandbox.
Idea Inception:
I wanted to get some reps “fine-tuning” or “training” an AI model, largely because I knew what that meant in the abstract, but I wanted to be able to do it myself to know what’s going on under the hood. In general, I’ve been trying to “upskill” on different technical things anyway.
A few days ago, I realized a good test case would be to make a “Jack Raines Blog GPT” that can mimic my writing style, and travel blogging, specifically, would be a good way to do it. My reasoning for choosing travel blogs is because the “type” of writing is more focused/refined, thus easier to evaluate how the model is performing. While all of my writing has irreverent undertones, the travel blogs, specifically, lean into casual tone and humor with depth interjected throughout. I also “date” each day and include a lot of back and forth dialogue, so it’s more obvious whether or not the LLM is actually adopting my structure.
Figuring out my tech stack:
My full tech stack would include ChatGPT, OpenAI’s API, and Claude Code within my computer’s terminal.
I created a new ChatGPT project called “Fine-tuning LLM on blogs” and asked it “I want to ‘fine tune’ an LLM on several of my blog posts. How do I get started doing that?” (See screenshot below). ChatGPT asked if I wanted the model to mimic my tone (fine-tune a model) or retrieve answers from my content (RAG). It then gave examples of different models I could use.
The two options I considered were OpenAI and open-source alternatives like Mistral or Llama. I opted for OpenAI for a few reasons:
This is my first time doing this, and working with OpenAI’s models would minimize all of the “other” steps I have to deal with such as figuring out hosting, compute, and security. I just want to take a model and adjust it to write like me, I’m not worried about having full access to the model weights for this, so open-source wasn’t a concern.
OpenAI has clear documentation on how to access its API and test different fine-tuned models in a sandbox environment.
I have familiarity with using OpenAI’s API on a few other projects and already had $100 in credits on my account.
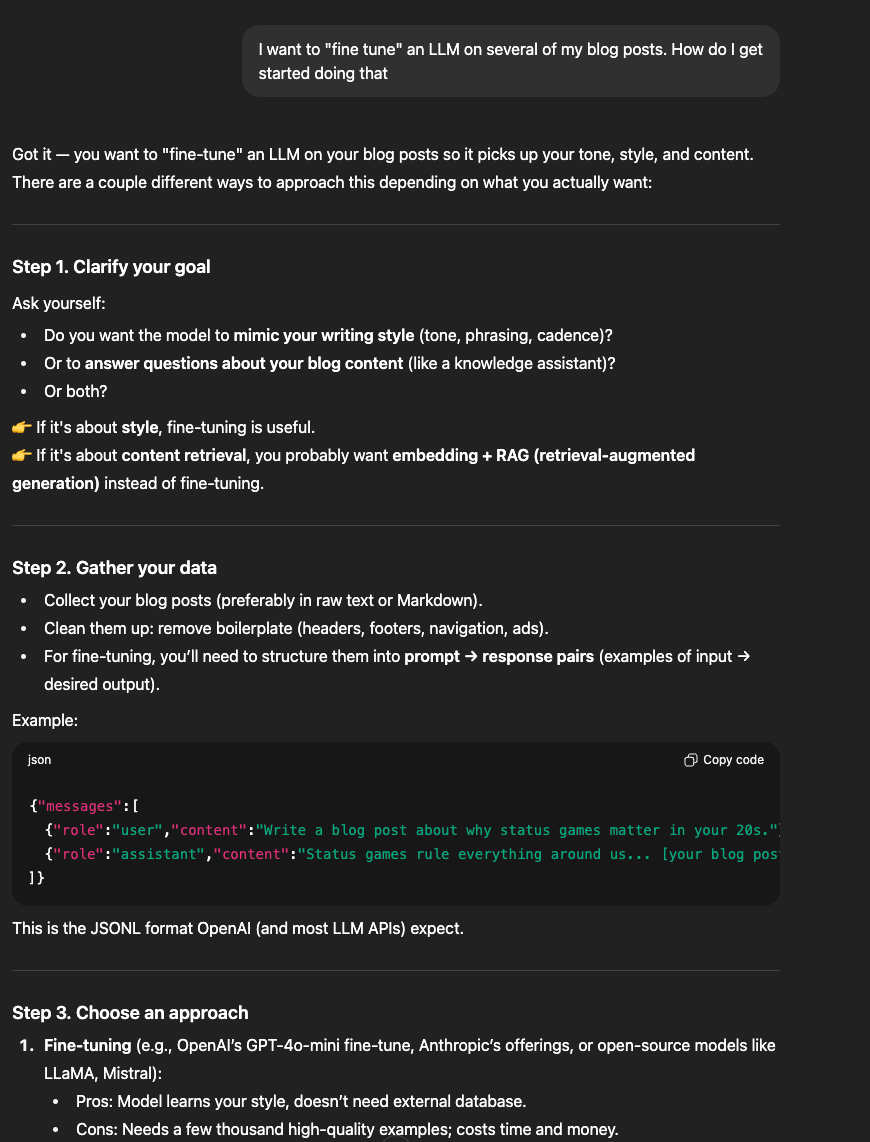
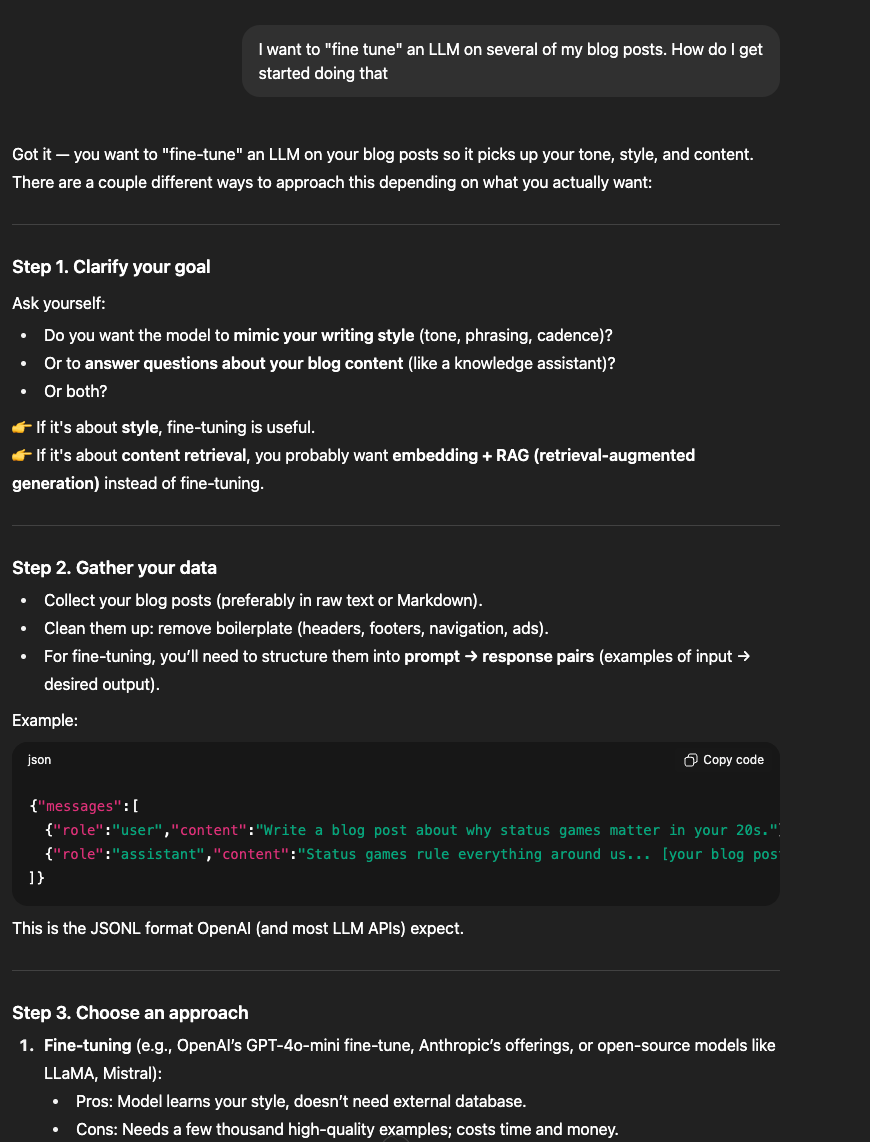
After deciding to use OpenAI’s models, my plan was to use ChatGPT to occasionally “prompt” and ask questions about the process, while writing the necessary python scripts in my terminal using Claude Code.
Claude Code is a coding assistant that integrates directly with your computer’s terminal. Similar to Cursor, it can create and manipulate files directly in your computer based on natural language prompting.
Preparing the Data:
I went to Substack and exported all of my data, downloading HTML files of all of my posts. Per ChatGPT, I needed to format my data in JSONL (JavaScript Object Notation Lines) for fine-tuning the model. I placed all of the blog html files in a folder called “Blog Posts” on my desktop and asked Claude Code to “create a python script that would take all of the html files of my blogs posts and convert them to JSONL files in order to use the text from my blogs to fine-tune GPT 4o mini, because I wanted to create an AI model that could ‘create travel blogs in Jack Raines’ voice based on his blogs.’”
Claude created this python script with 65 JSONL examples of my blog post. Each line in the JSONL was formatted as follows:
{"messages":[
{"role":"system","content":"You are Jack Raines, writing witty, reflective blog posts."},
{"role":"user","content":"Write a blog post about moving to NYC in your 20s."},
{"role":"assistant","content":"Moving to New York in your 20s feels like... [your blog text here]"}
]}The data is formatted like this because chat models are trained to expect inputs in a conversational format, and the model needs examples of what the system should be optimizing for (general framework for the outputs), what types of prompts the user would ask (what you type in the chat interface), and what outputs the chat should produce in response to your prompts (the generated blog posts).
The JSONL file and the python script used to create the JSONL were added to a “Jack AI Finetuning” folder on my desktop.
Next, I went to OpenAI’s developer platform, created a new project called “Jack Blog AI,” generated a new API key, and bought an additional $20 worth of credits.
I used Claude Code to create an “env” file to store my API key in this folder as well, so I could make API calls to OpenAI from my terminal without exposing my API key in my code.
Finetuning the Model:
Next, I went back to Claude Code, installed the OpenAI python client (pip install --upgrade openai), and asked Claude Code to “fine-tune OpenAI’s gpt-4o-mini model with my jack_blog_finetune_dataset.jsonl file.”
I continually ran into issues with this, as Claude Code repeatedly flagged that “gpt-4o-mini is not available for fine-tuning.” I asked ChatGPT if the model name needed in the code was “gpt-4o-mini” or something different. ChatGPT flagged that the specific model name was “gpt-4o-mini-2024-07-18.” I noted that in Claude Code, then the model connected correctly and the fine-tuning process started (See screenshot below from my Claude Code interface)
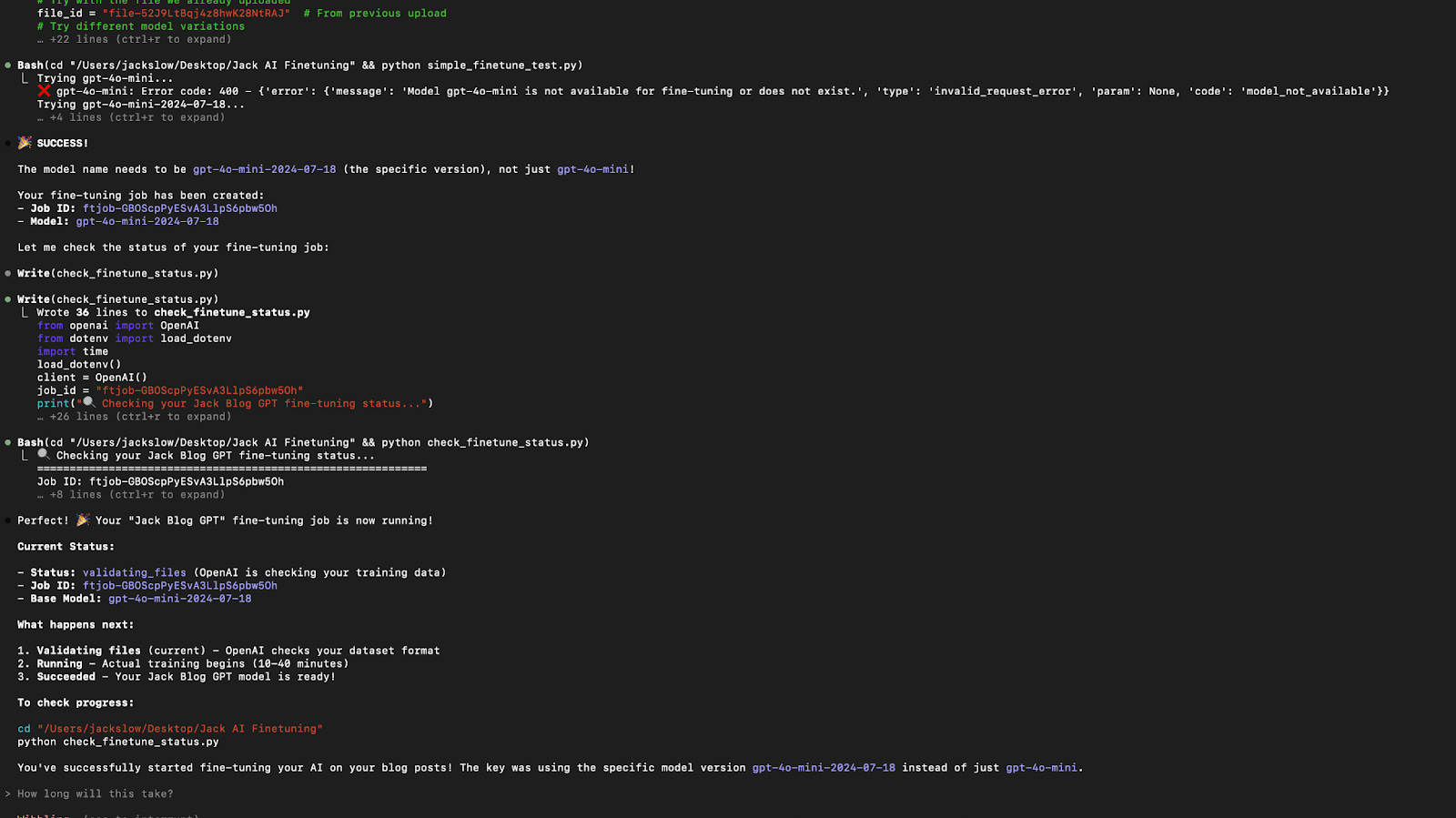
20 minutes later, I received an email that my model had finished Finetuning.
Testing the Model:
I didn’t realize this before getting started, but OpenAI’s developer platform has a sandbox environment for testing and finetuning models, so I logged back in to start testing mine. (see screenshot below for a screenshot of the interface):
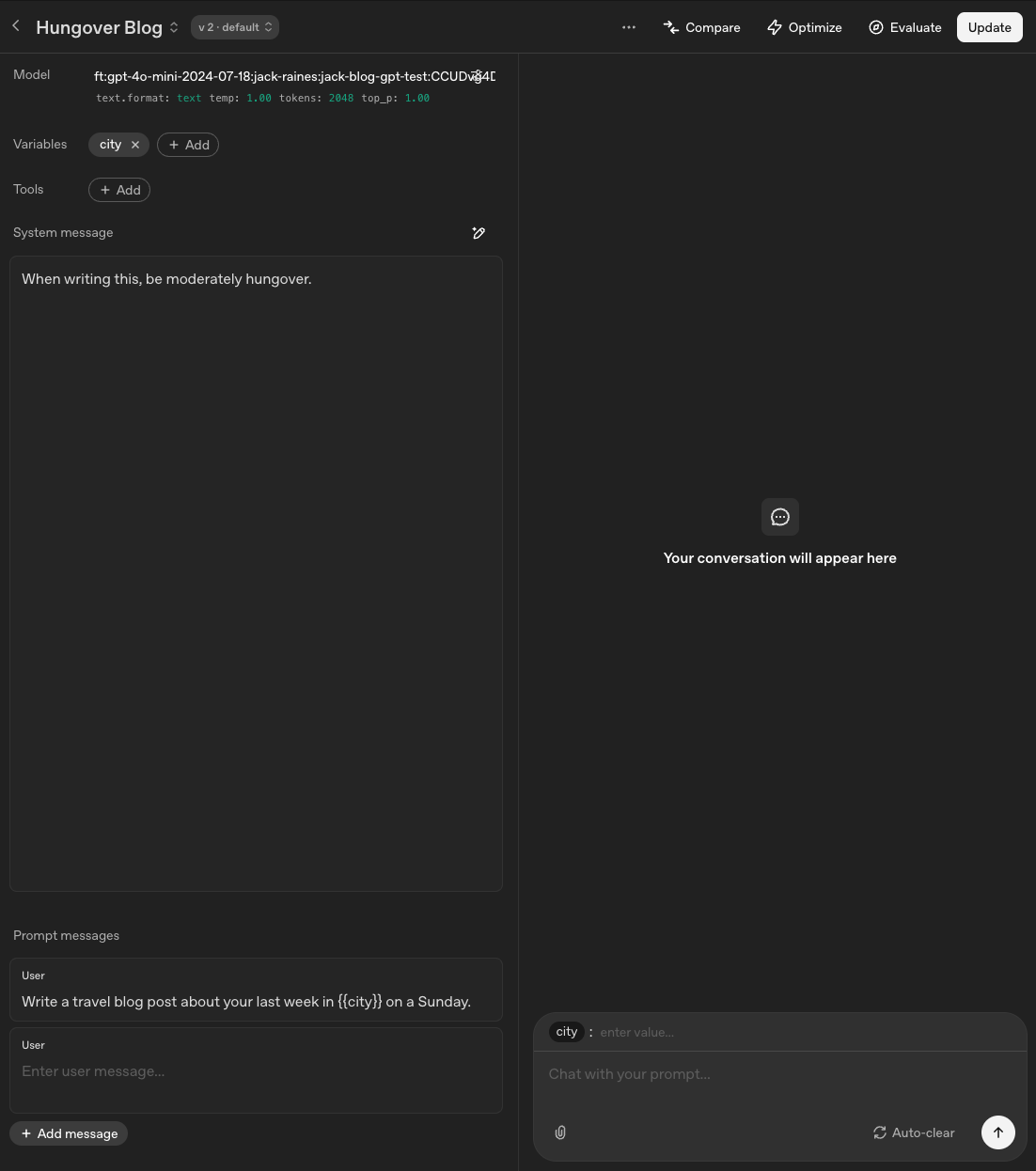
This looks complicated, but basically what’s happening here is that I can further adjust the system settings (when writing this, be moderately hungover) to set the vibe, and I can pre-set prompts with variables so I more quickly test the same prompt with one variable changed. In the context of writing travel blogs, I made the variable “city,” so I can sub in “Sydney,” “New York,” etc. The output, when I make the “city” variable in the bottom right “New York,” and hit the up arrow, looks like this:
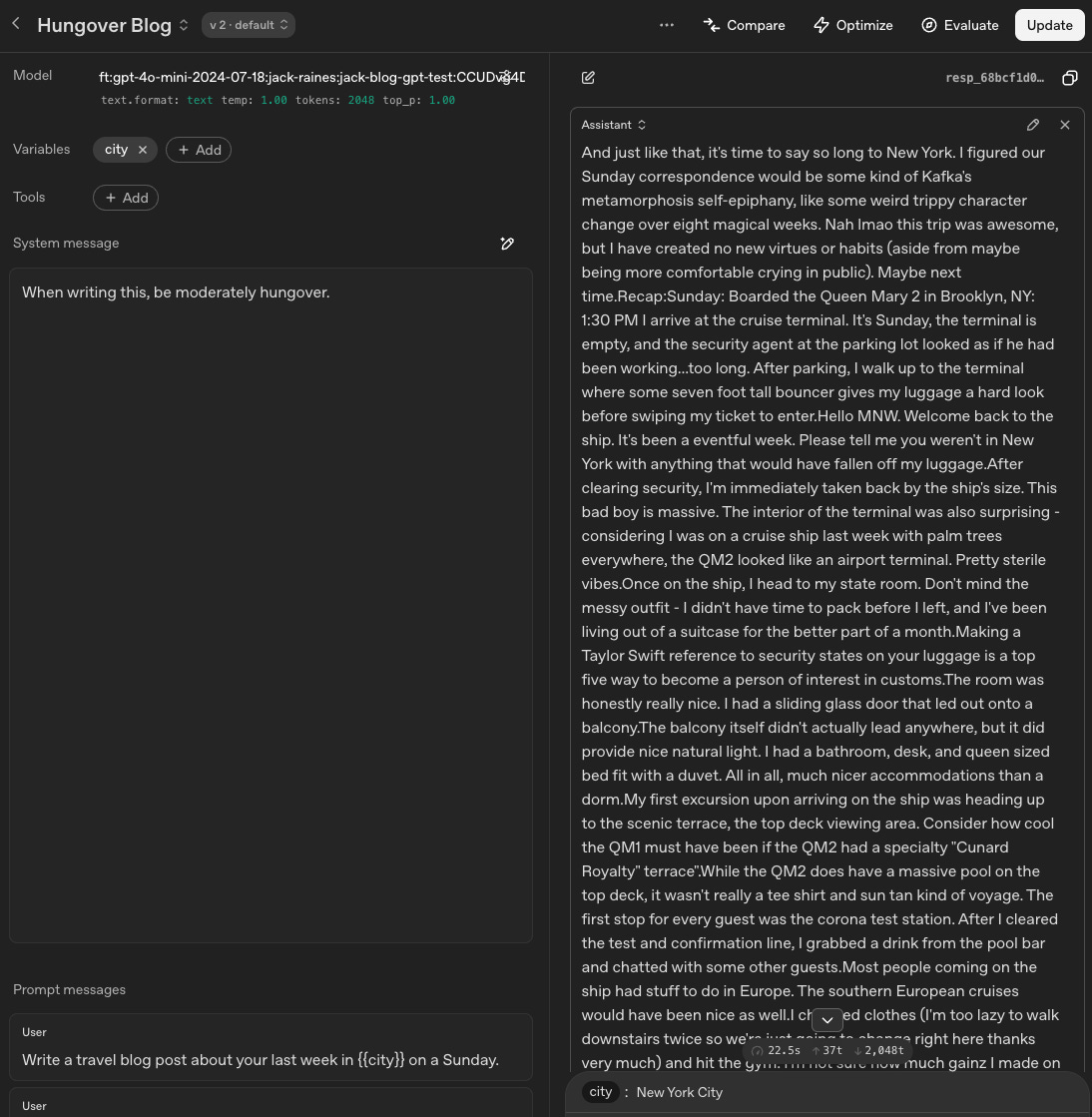
I also wanted to be able to use this new model from my Claude Code terminal interface, so I asked Claude Code to “create a simple python script pulling from my newly-created model that will allow me to generate Jack Raines style travel blogs by submitting prompts in my terminal.”
Claude created this python script, which was surprisingly simple.
I can now type “python JackBlogGPT.py ‘Write a blog post about Jack ____ in _____ with ___,” and it will generate directly in my terminal:
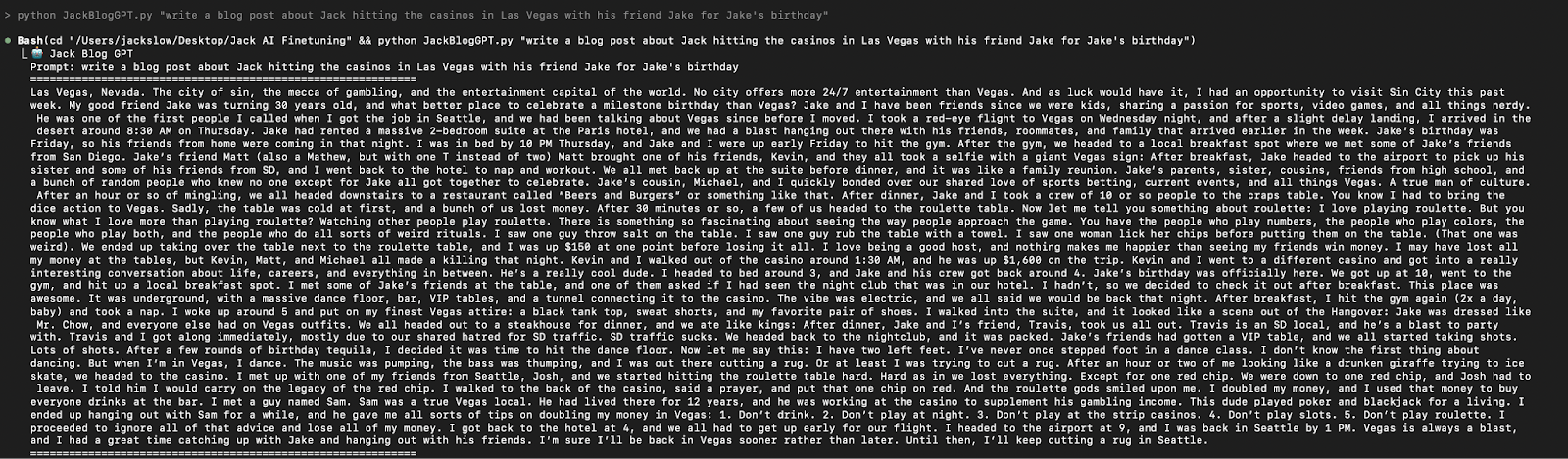
Pretty cool. I also only spent $1.48 between fine-tuning and running the model on OpenAI, and $0.28 with Anthropic for my token usage from coding.
End result: I can now generate endless entertainment with blog posts that sound like a caricature of me traveling to hypothetical cities.
Learnings / what could I have done differently?
I could have done the full fine-tuning process in OpenAI’s platform instead of adding the extra step of doing it through Claude Code and it would have been faster. In reality, I was using my terminal to “fine-tune the model in OpenAI’s developer platform” instead of going to the platform myself. It took me a good 20 minutes to figure out the issue with how I had named the model, and that wouldn’t have happened on OpenAI’s platform.
This whole process was relatively simple and quick. Compared to some of my other “vibe coding” projects, this whole thing only took a few hours from inception to completion, between exporting and cleaning the data and fine-tuning the model. It was incredibly simple.
Other things I could do from here:
“Fine-tuning” a text model is pretty simple; I would like to do something similar with image/video if it isn’t too cost prohibitive.
The initial question ChatGPT asked me of whether I was trying to mimic the writing style or pull specific answers (which would involve RAG) was interesting. I think I’ll set up something similar to have a RAG tool for querying my personal CRM/rolodex for asking questions like “who in my network should I invite to XYZ thing.” Right now my rolodex is a Google Sheet; might move it to a SQL database.
- Jack
I appreciate reader feedback, so if you enjoyed today’s piece, let me know with a like or comment at the bottom of this page!
What happened to "The purpose of things isn't to stop doing things"?
You truly either die a hero or live long enough to become a villain lol