
Forward Deployed Hedge Fund Analysts
Straight of Hormuz, OpenAI's new acquisition, and Mercor got hacked.

Welcome to Young Money! If you’re new here, you can join the tens of thousands of subscribers receiving my essays each week by adding your email below.
Happy Monday, to those who celebrate. Last week was quite busy on the Slow Ventures front. We hosted an Etiquette School in NYC on Tuesday evening, then an “AI bots training school” for creators in San Francisco on Thursday and Friday. I also turned 29 last week. One more year until I’m officially washed. Okay let’s get into it.
Forward Deployed Hedge Fund Analysts:
An idea I’ve had for a while now is that market cycles move faster, and more violently, than in the past because information disseminates quicker than ever before thanks to X and Reddit. Online narratives around stocks are like crack cocaine for market reflexivity. LLMs have only accelerated that trend.
A good working model of the investing world in the age of AI is that any data that is publicly available will be instantly reflected in market participants’ models. “Crunching the numbers” isn’t edge when AI can both gather all publicly-available data and integrate that data in any and all relevant models instantaneously. Wire your computer to constantly parse EDGAR filings and tap into the X API for real-time coverage of relevant stocks, and AI can now process information far faster than was ever possible for humans.
In a world where AI can both gather and process all publicly available information instantly, the only “real” edges left are 1) access to hidden information and 2) discernment over what information should be discarded. On the second point: when you have unlimited tokens at your disposal, “analysis paralysis” is a greater threat than ever before. You can always look at “another thing,” even though any good investment comes down to 1 or 2 things that really matter. But that’s a topic for a later blog post; for now, I’d like to focus on point 1) hidden information.
In the private markets, hidden information means that you know a hot founder is raising for their new company before that becomes public knowledge. Either you know the founder directly, or a mutual friend makes an introduction, but you are granted “access” to that information before it became public knowledge, therefore positioning you to act on that information before everyone else. This has, of course, always been the way venture capital has worked, particularly at the seed stage. The only difference now is how quickly you can speedrun the “research” part of your diligence (mapping out competitors, understanding the technology itself, etc). Access + discernment are the only games in town.
In the public markets, hidden information is… a bit different. You, obviously, can’t coerce material nonpublic information (MNPI) from executives of public companies. That’s a great way to end up in prison. But you can, however, go find information that could be, but currently is not public. One way to find that information might be sending your analyst on a speedboat to the Strait of Hormuz.
Last week, investment research firm Citrini did just that…
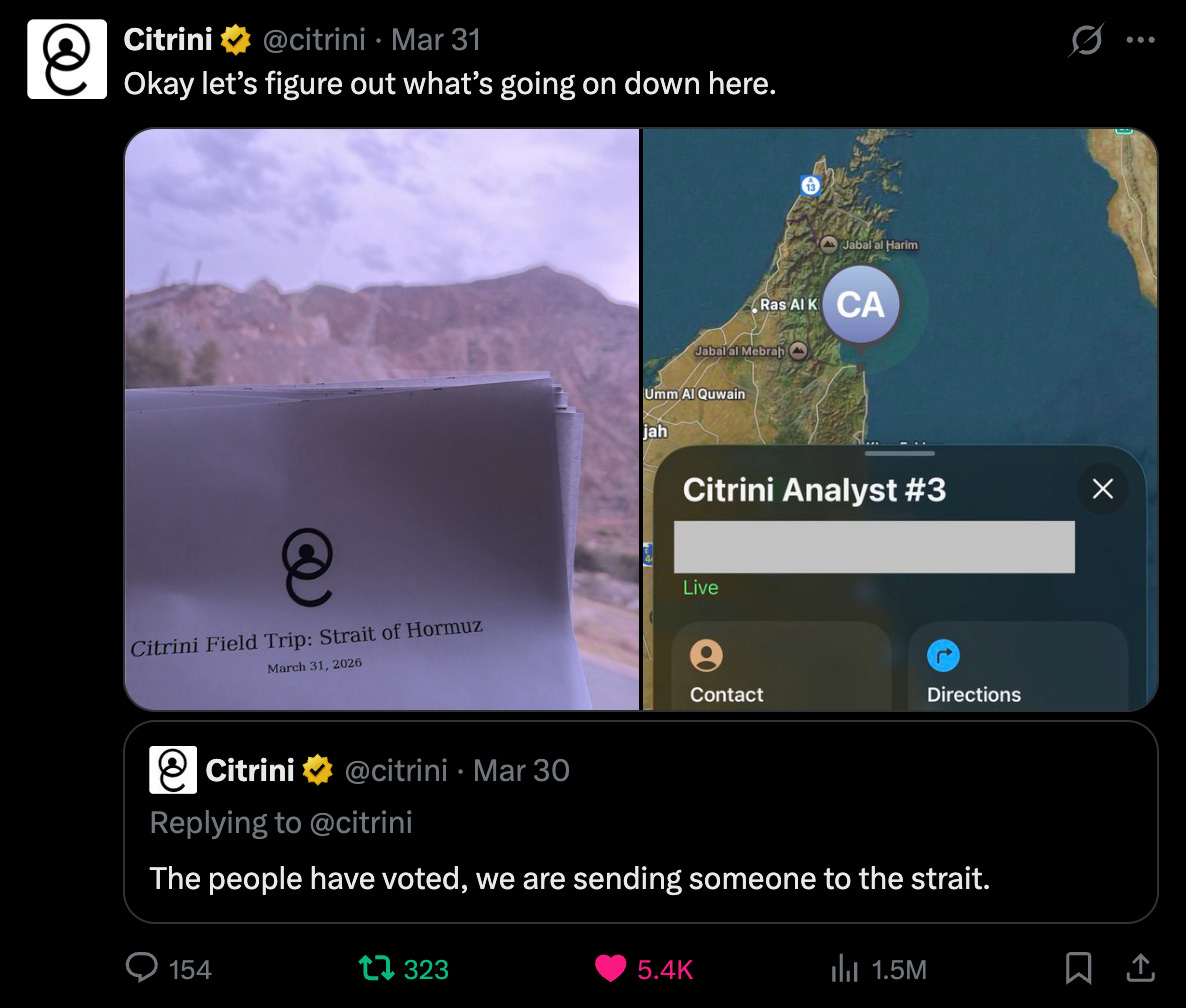
And on Sunday evening, they published a “field trip” recap, both detailing the adventure in Oman (events include, but are not limited to, near arrests, in-person footage of ships on fire, and drones buzzing overhead their dingy) and providing actionable investment takeaways stemming from what their analyst saw in the Strait. (See below for the full piece):

I mentioned above that analysis paralysis is a real threat to the investment process with AI being able to ingest, well, everything. Combine that with the fact that AI slop is bombarding social channels left and right, and it becomes difficult to know what’s real, and what’s worth ingesting, in the first place. Over the last few weeks, for example, there’s been so much fake footage of bombings in the Middle East (either claiming the wrong location, or, quite literally, just AI-generated slop), that it’s impossible to sift through the noise. One way to know what’s real, then, is to see it first-hand. In an interview with Lex Fridman, Jeff Bezos said, “I have a saying, which is when the data and the anecdotes disagree, the anecdotes are usually right…” In a world with infinite data, anecdotes, such as eyewitness reports from an analyst that you send to Oman, can be quite valuable.
Citrini is a research publication that also trades its own book, and in this case, they did adjust their portfolio positioning based on what their analyst saw in the Strait, from tanker traffic to anecdotes from Omanis and Iranians he met sharing their thoughts on how they believed the conflict would play out.
While I don’t necessarily think every Tiger Cub is going to start sending analysts to Ukraine, I do think that as LLMs continue to commoditize the gathering and modeling of public information, more “journalistic” approaches to investing will drive more and more alpha. IRL investigation is also one of few things that AI won’t, at least for the foreseeable future, be able to disrupt.
OpenAI Buys TBPN:
Three weeks ago, OpenAI claimed that they were going to “cut back on side projects” and focus on nailing their core business; aka coding and enterprise. The reason? Anthropic started kicking their ass as of late, both in revenue growth rate and “vibes.”
In January 2025, OpenAI’s annualized revenue was $6 billion and Anthropic’s was $1 billion. By October 2025, OpenAI’s was $13 billion and Anthropic’s was $7 billion. By March? Anthropic had reached $19 billion in annualized revenue, closing in on OpenAI’s decelerating annualized revenue (~$25 billion in February).
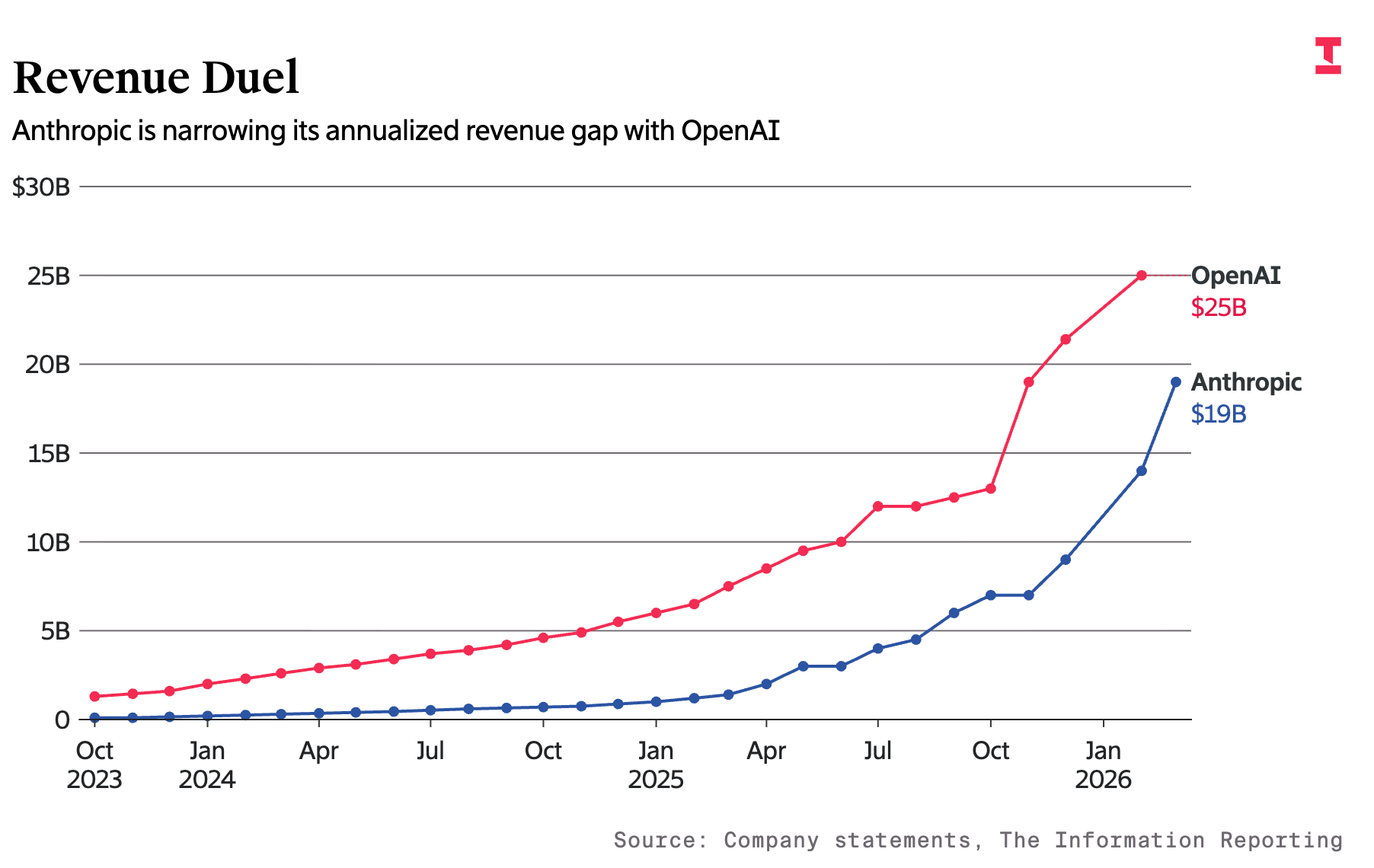
Anthropic has taken a very, very focused approach to AI. For starters, they never released any video or image generation product. From 2023 through early 2025, their only “consumer” product was their chatbot, and they offered API access for their models to enterprise customers. Then, in February 2025, they released “Claude Code,” and it took the internet by storm. Claude Code was the first AI product that, for a lot of people, offered a glimpse into what “autonomous coding” could look like. By typing “claude” into your terminal, you could describe what you wanted in English (or Spanish, Japanese, whatever) to your computer, and it would just… build it. Early on, it made a lot of mistakes, and you had to regularly re-prompt it, but, still, it was magic. And it’s only gotten better. When models experienced a step function improvement in November, Claude Code got really, really good. Like, “spend 15 minutes brainstorming a task, tell it to go “cook,” and let it do its thing” good. By this point, OpenAI had countered with the launch of Codex (its version of Claude Code), but Claude Code had run away with the mindshare by 1) being first and 2) (more importantly) being consistent.
OpenAI, over the last 3.5 years, has launched ChatGPT (which has had its own ridiculous set of model names, from “mini” to “turbo” to “o1-preview” to “01-mini.” Like, seriously, who can keep up with these?), DALL-E (text-to-image), Sora (its now-cancelled text-to-video “social platform”, Codex (coding assistant), Frontier (agent-management platform), Atlas (browser), an unnamed consumer hardware device (they acquired Jony Ive’s startup for billions), custom chips, “adult mode”, and ChatGPT Health.
Anthropic had Claude and Claude Code. It turns out that developers will pay a lot of money to use Claude Code, so they doubled, tripled, and quadrupled down on Claude and Claude Code. Pretty much all of their product releases have just been improvements to these two tools: either integrating Claude into other platforms (Claude for Excel and Claude for Powerpoint) or adding new features to Claude Code (skills, plugins, Claude Cowork). Much easier to get the messaging right and win customer trust when you’re only selling a couple of things.
So it’s not a shocker that a few weeks ago, OpenAI’s “CEO of applications,” Fidji Simo, sent around a memo claiming the company would be cutting back on side projects. Then, two weeks later, they acquired daily tech show TBPN for ‘low hundreds of millions.’ The $100 million question on X last week was, “What did OpenAI actually buy?”
I love TBPN (which was basically Sportscenter for people who know what “reinforcement learning” is). I know John and Jordi fairly well, I’ve been on the show a couple of times myself, and they invented a novel, new media format that was expected to do ~$30 million top-line this year. Good for them for getting their bag; but there’s just no way, (regardless of what a lot of folks on Twitter are saying) that this was a “distribution” purchase.
This deal was likely on par with Joe Rogan’s latest Spotify deal, worth $250 million. Between Youtube and Spotify alone, Joe Rogan averages ~4 million+ views per episode. TBPN averaged something like ~70,000 viewers per episode across platforms. Sam Altman’s Twitter account, with 4.6m followers, has greater “distribution” than TBPN. So a 9-figure acquisition in the midst of a “no more side quests” command from management is.. interesting.
My $0.02? OpenAI’s vibes have been cooked for the last ~six months, they’re trying to push through an IPO by the end of the year while the market is increasingly skeptical of their valuation, and Jordi and John have the best marketing and comms chops in tech right now. Paying ~$200 million, when you were last valued at ~$850 billion (0.024% of your enterprise value) is actually a really low price to pay for a couple of guys who just might fix your brand perception, particularly when AI research talent is routinely getting acqui-hired for billions of dollars. And that’s the right framing to look at this from, by the way: talent acquisition, not “buying distribution” or “the future of media” or whatever.
Altman / OpenAI realize that they need to fix their public image ASAP in this ramp towards an IPO. Jordi and John both understand how to 1) capture the narrative and 2) charm OpenAI’s target market (tech investors, entrepreneurs, and developers). They also almost-certainly realized that, if they were to take a deal from OpenAI, Anthropic, or any other big tech platform, their credibility would be, at least slightly, tainted when they were critiquing AI platforms. Even if they are actually editorially independent, there will be an inherent level of audience skepticism toward their AI takes now that OpenAI owns them. To be “okay” with the opportunity cost of the drop in perceived independence (particularly when they were set to make ~$30m this year), it was going to take a big number, and OpenAI hit their ask.
Sure, paying a “forward revenue multiple” of ~7-10x 2026 revenue for a daily tech show sounds high, but this was never about the business. They’re winding down their ad business post-acquisition; OpenAI couldn’t care less about the ad revenue. This is about hiring the talent that they think could help them “control the narrative.” And $200 million is cheap if it increases your odds of a $1 trillion IPO.
Mercor’s Big Security Lapse:
AI models, like ChatGPT and Claude, train on data. Much of that initial training data was scraped from the internet. Blog posts, Github code bases, Youtube videos, tweets, etc. Most of that publicly available data has now been fully ingested and picked over. But AI labs can further improve their models through practices known as “supervised fine-tuning” and “reinforcement learning.” In the former, humans write high-quality responses to prompts to teach the AI “how to answer,” and in the latter, humans compare two model outputs and select the superior one.
AI labs need a supply of humans to provide these data-training tasks, and Mercor fills that gap. If you go on their website right now, you’ll see “find remote work opportunities.”

Those opportunities involve, essentially, creating workflows that mirror what you do in your job, and selling those workflows to AI labs via Mercor. For your efforts, you’ll earn anywhere from ~$50 to $150 per hour, or ~$500 to ~$1,000 per project. Put differently, you’re being paid to help train AI models to do your job.
(I don’t fall in the full dystopian camp that thinks AI will kill the labor market or whatever, and I think people are quite malleable, but the fact that AI labs are paying willing contractors hundreds of millions of dollars to help them train AI to do their jobs is a bit.. wild).
To land one of these opportunities, you take a recorded “AI interview,” your information is saved, and then you can apply for open positions on their site. Here’s a couple of example job listings for “audio and video technicians” and, hysterically, “basketball experts.”


Through this process of interviewing candidates and collecting their submission data, Mercor collected a massive data set on 10s of thousands of contractors, including personal identification information, videos of workflows, screenshots of their screens, and, obviously, videos of them interviewing and performing these tasks. This is, obviously, valuable training data, given that labs are paying millions of dollars to acquire it.
And last week, 4TB of data, including candidate profiles, PII, employer data, source code, API keys, video interviews, and customer data, ended up in the hands of Lapsus$ group (according to Lapsus$). The brief play-by-play:
A month ago, a hacker group called TeamPCP exploited a misconfiguration in the GitHub actions workflow of Trivy, an open-source vulnerability scanner.
They leveraged that hack to push a malicious Trivy version live.
LiteLLM, an open-source Python library that routes API calls to different LLM providers, installed and ran Trivy, infecting LiteLLM and giving the hackers access to LiteLLMs publishing credentials.
The hackers then pushed a malicious LiteLLM update. The malicious LiteLLM was live for ~40 minutes.
Mercor uses LiteLLM to route data to different AI labs, so the hackers were able to steal Mercor’s credentials and access an alleged ~4TB of data.
That data then ended up on other hacker group Lapsus$’s website, up for auction.
It’s not clear if this was the only data breach Mercor suffered (it would be difficult to steal ~4TB of data in ~40 minutes, though there’s no evidence of other exploits thus far). The result: 4TB of really valuable training data could very well have gotten leaked to whatever bad actor bid the most.
Woof.
The Mercor data has since been removed from Lapsus$’s site (I don’t know if that means Mercor cut a deal, they sold it to a 3rd party, or something else), but Mercor’s future now looks bleak: Meta paused its deals with the platform to investigate the breach, while other labs are also reevaluating their relationship with the platform.
The problem facing Mercor, now, isn’t just that they’ve lost customer trust. They product also just isn’t all-that defensible. Mercor offered a top-of-funnel for quality training data. Scale AI does the same thing. As does Surge AI. And probably several other companies whose names end in “AI.” Even if Mercor had, initially, been the “better” platform, exposing customer and contractor data to hacker groups is 100% grounds for reconsidering your data vendor, especially when there are similarly-positioned competitors ready to take your money right now. The result? I would not want to have been a Series C investor at $10 billion.
That being said, this does highlight a growing trend: AI both 1) makes hackers exponentially more proficient and 2) has made potential security breaches exponentially more common as former non-coders are now trying to build stuff (and have no idea how to handle security) and even experienced engineers are increasingly automating their outputs, introducing more surface areas for dangerous code. I think we’ll consider to see more and more hacks like this.
- Jack
I appreciate reader feedback, so if you enjoyed today’s piece, let me know with a like or comment at the bottom of this page!
Couldn't agree more with your last sentence about these types of hacks becoming more and more common.
Just last week a major JavaScript library axios (weekly downloads in the 10s of millions) shipped a compromised version --
https://www.axios.com/2026/03/31/north-korean-hackers-implicated-in-major-supply-chain-attack